

This blog post survey the attacks techniques that target AI (artificial intelligence) systems and how to protect against them.
At a high level, attacks against classifiers can be broken down into three types:
- Adversarial inputs, which are specially crafted inputs that have been developed with the aim of being reliably misclassified in order to evade detection. Adversarial inputs include malicious documents designed to evade antivirus, and emails attempting to evade spam filters.
- Data poisoning attacks, which involve feeding training adversarial data to the classifier. The most common attack type we observe is model skewing, where the attacker attempts to pollute training data in such a way that the boundary between what the classifier categorizes as good data, and what the classifier categorizes as bad, shifts in his favor. The second type of attack we observe in the wild is feedback weaponization, which attempts to abuse feedback mechanisms in an effort to manipulate the system toward misclassifying good content as abusive (e.g., competitor content or as part of revenge attacks).
- Model stealing techniques, which are used to “steal” (i.e., duplicate) models or recover training data membership via blackbox probing. This can be used, for example, to steal stock market prediction models and spam filtering models, in order to use them or be able to optimize more efficiently against such models.
This post explores each of these classes of attack in turn, providing concrete examples and discussing potential mitigation techniques.
This post is the fourth, and last, post in a series of four dedicated to providing a concise overview of how to use AI to build robust anti-abuse protections. The first post explained why AI is key to building robust protection that meets user expectations and increasingly sophisticated attacks. Following the natural progression of building and launching an AI-based defense system, the second post covered the challenges related to training classifiers. The third one looked at the main difficulties faced when using a classifier in production to block attacks.
This series of posts is modeled after the talk I gave at RSA 2018. Here is a re-recording of this talk:
RSA talk 2018You can also get the slides here.
Disclaimer: This post is intended as an overview for everyone interested in the subject of harnessing AI for anti-abuse defense, and it is a potential blueprint for those who are making the jump. Accordingly, this post focuses on providing a clear high-level summary, deliberately not delving into technical details. That said, if you are an expert, I am sure you’ll find ideas, techniques and references that you haven’t heard about before, and hopefully you’ll be inspired to explore them further.
Adversarial inputs
Adversaries constantly probe classifiers with new inputs/payloads in an attempt to evade detection. Such payloads are called adversarial inputs because they are explicitly designed to bypass classifiers.
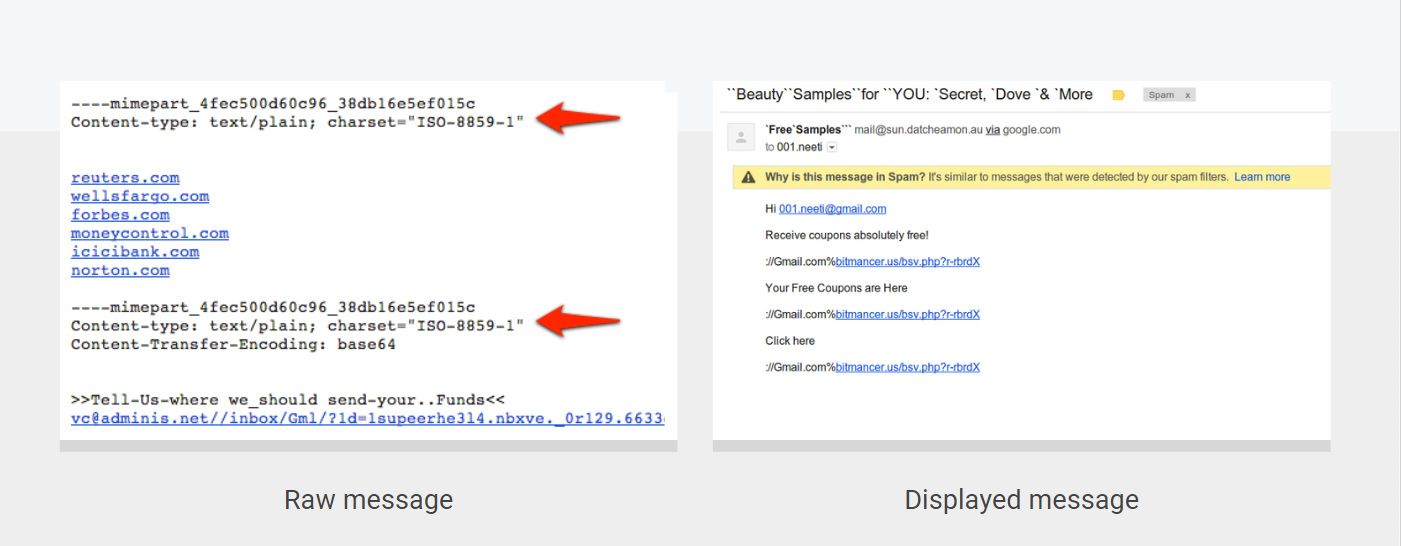
Here is a concrete example of an adversarial input: A few years back, one clever spammer realized that if the same multipart attachment appeared multiple times in an email, Gmail would only display the last attachment as visible in the screenshot above. He weaponized this knowledge by adding an invisible first multipart that contained many reputable domains in an attempt to evade detection. This attack is a variation of the class of attacks known as keyword stuffing.
More generally sooner or later classifiers face two types of adversarial input: mutated inputs, which are variations of a known attack specifically engineered to avoid your classifier, and zero-day inputs, which are never-seen-before payloads. Let’s explore each of these in turn.
Mutated inputs
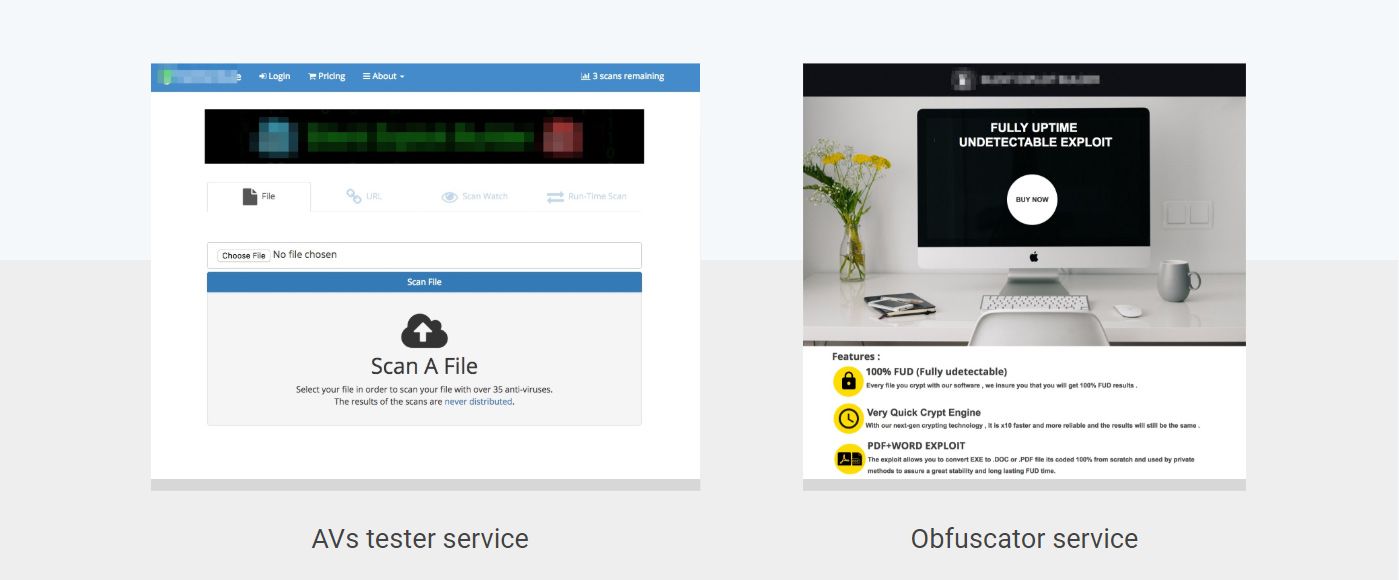
Over the last few years we have seen an explosion of underground services designed to help cybercriminals craft undetectable payloads best known in the underworld as “FUD” (fully undetectable) ones. These services range from testing services that allow to test payloads against all anti-virus software, to automated packers that aim to obfuscate malicious documents in a way that makes them undetectable (with a warranty!). The screenshot above showcases two such services.
This recrudescence of underground services specialized in payload crafting emphasizes the fact that:
Therefore, it is essential to develop detection systems in such a way that they makes it hard for attackers to perform payload optimization. Below are three key design strategies to help with that.
1.Limit information leakage

The goal here is to ensure that attackers gain as little insight as possible when they are probing your system. It’s important to keep the feedback minimal and delay it as much as possible, for example avoid returning detailed error codes or confidence values.
2. Limit probing
The goal of this strategy is to slow down attackers by limiting how often many payload they can test against your systems. By restricting how much testing an attacker can perform against your systems, you’ll effectively reduce the rate at which they can devise harmful payloads.
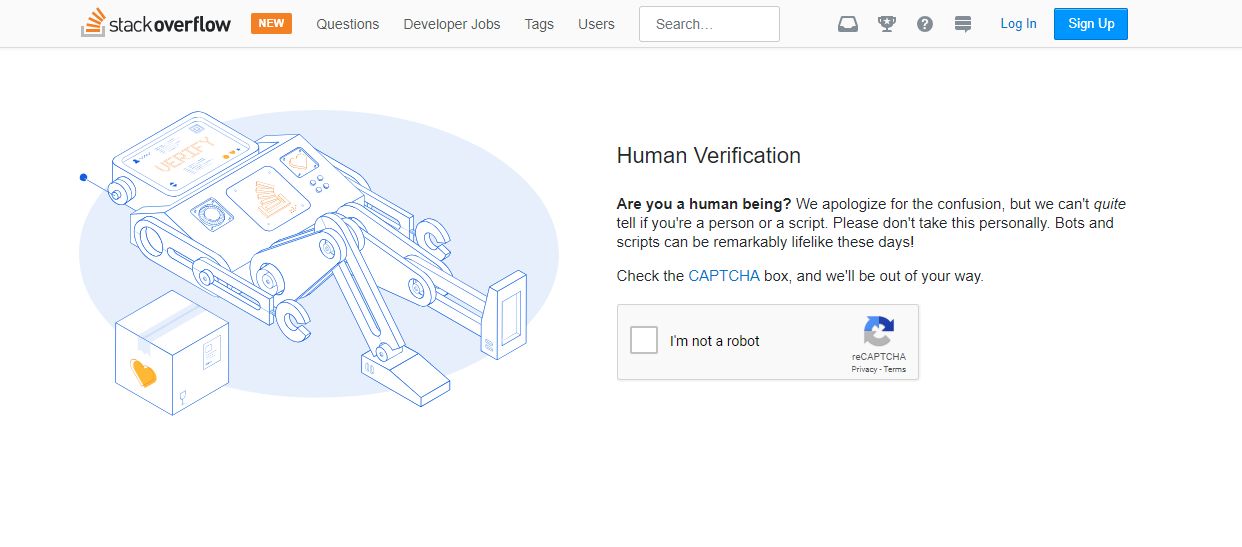
This strategy is mostly carried out by implementing rate limiting on scarce resources such as IP and accounts. A classical example of such rate limiting is to ask the user to solve a CAPTCHA if he is posting too frequently as illustrated above.
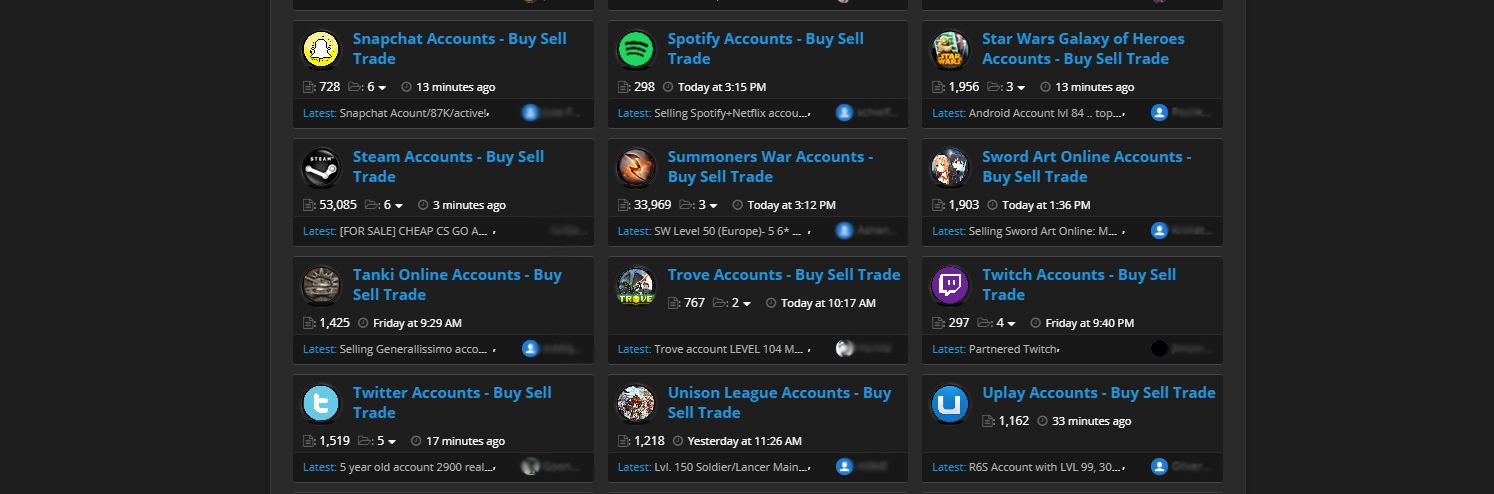
The negative side effect of such active rate limiting is that it creates an incentive for bad actors to create fake accounts and use compromised user computers to diversify their pool of IPs. The widespread use of rate limiting through the industry is a major driving factor behind the rise of very active blackmarket forums where accounts and IP addresses are routinely sold, as visible in the screenshot above.
3. Ensemble learning
Last, but not least, it’s important to combine various detection mechanisms to make it harder for attackers to bypass the overall system. Using ensemble learning to combine different type of detection methods, such as reputation-based ones, AI classifiers, detection rules and anomaly detection, improves the robustness of your system because bad actors have to craft payloads that avoid all those mechanisms at once.
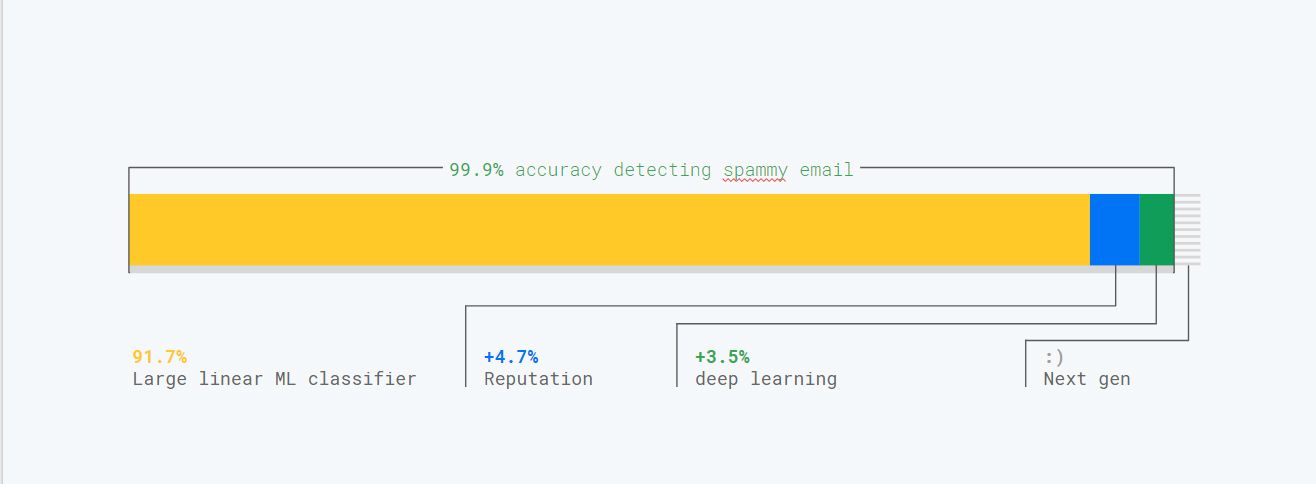
For example as shown in the screenshot above, to ensure Gmail classifier robustness against spammers we combine multiple classifiers and auxiliary systems. Such systems include a reputation system, a large linear classifier, a deep learning classifier and a few other secret techniques ;)
Examples of adversarial attacks against deep neural networks

A very active related research field is how to craft adversarial examples that fool deep-neural networks (DNNs). It is now trivia to create imperceptible perturbation that completely fools DNN as shown in the screenshot above, taken from this paper.
Recent work suggests that CNN are vulnerable to adversarial input attack because they tend to learn superficial dataset regularity instead of generalizing well and learning high-level representation that would be less susceptible to noise.
This type of attack affects all DNN, including reinforcement-based ones, as highlighted in the video above. To learn more about such attacks, you should read Ian’s intro post on the subject or start experimenting with Clever Hans.
From a defender perspective, this type of attack has proven (so far) to be very problematic because we don’t yet have an effective way of defending against such attacks. Fundamentally, we don’t have an efficient way to get DNNs to generate good output for all inputs. Getting them to do so is incredibly hard because DNNs perform nonlinear/non-convex optimizations within very large spaces and we have yet to teach them to learn high level representation that generalize well. You can read Ian and Nicolas’ in-depth post to know more about this.
Zero-day inputs
The other obvious type of adversarial inputs that can completely throw off classifiers are new attacks. New attacks don’t happen very often, but its’ still important to know how to deal with them as they can be quite devastating.
While there are many unpredictable underlying reasons why new attacks emerge, in our experience the following two types of events are likely to trigger their emergence:
New product or feature launch: By nature adding functionalities opens up new attack surfaces that attackers are very quick to probe. This is why it is essential (and yet hard) to provide day zero defense when a new product launches.
Increased incentive: While rarely discussed, many new attacks surge are driven by an attack vector becoming very profitable. A very recent example of such behavior is the rise of abusing cloud services such as Google Cloud to mine cryptocurrencies in response to the surge of bitcoin price late 2017.
As bitcoin prices skyrocketed past $10,000, we saw a surge of new attacks that attempted to steal Google cloud compute resources to mine. I will cover how we detected those new attacks a little later in this post.

All in all, the Black Swan theory formalized by Nassim Taleb applies to AI-based defenses, as it does with any type of defense:
Sooner or later an unpredictable attack will throw off your classifier and it will have a major impact.
However, it is not because you can’t predict which attacks will throw off your classifier, or when such an attack will strike that you are powerless. You can plan around such attacks happening and put in place contingency plans to mitigate it. Here are a few directions to explore while preparing for black swan events.
1. Develop an incident response process
The first thing to do is to develop and test an incident recovery process to ensure you react appropriately when you get caught off guard. This includes, but is not limited to, having the necessary controls in place to delay or halt processing while you are debugging your classifiers, and knowing who to call.
The (free) Google SRE (Site Reliability Engineering) handbook has a chapter on managing incidents, and another on emergency responses. For a more cybersecurity-centric document you should look at the NIST (National Institute of Standards and Technology) cybersecurity event recovery guide. Finally, if you’d rather watch a talk instead, take a look at the video on how Google runs its Disaster Recovery Training (DiRT) program, and the video on how Facebook do incident response (the recording don’t show the slides)
2. Use transfer learning to protect new products
The obvious key difficult is that you don’t have past data to train your classifiers on. One way to mitigate this issue is to make use of transfer learning, which allows you to reuse already existing data from one domain, and apply it to another.
For example, if you’re dealing with images you can leverage an existing pre-trained model, while if you’re dealing with text you can use public datasets such as the Jigsaw dataset of toxic comments.
3. Leverage anomaly detection
Anomaly detection algorithms can be used as a first line of defense because, by nature, a new attack will create a never previously encountered set of anomalies related to how they exploit your system.

An historical example of a novel attack triggering a swath of new anomalies was the “MIT gambling syndicate” attack against the Massachusetts WinFall lottery game.
Back in 2005, multiple groups of gambling syndicates discovered a flaw in the WinFall lottery system: when the jackpot was split among all participants, you would earn $2.3 on average for each $2 ticket you bought. This split, known as a “roll-down,” occurred every time the pool of money exceeded $2 million.
To avoid sharing the gains with other groups, the MIT gang decided to trigger a roll-down way ahead of time by performing a massive buyout of tickets three weeks before a roll-down was expected. Obviously, this massive surge of tickets—bought from very few retailers—created a host of anomalies that were detected by the lottery organization.

More recently, as alluded to earlier in this post, when Bitcoin prices rose like crazy in 2017 we started to see an army of bad actors trying to benefit from this surge by mining using Google cloud instances for free. To acquire instances for “free,” they attempted to exploit many attack vectors that included trying to abuse our free tier, use stolen credit cards, compromise legitimate cloud users’ computers, and hijack cloud users’ accounts via phishing.
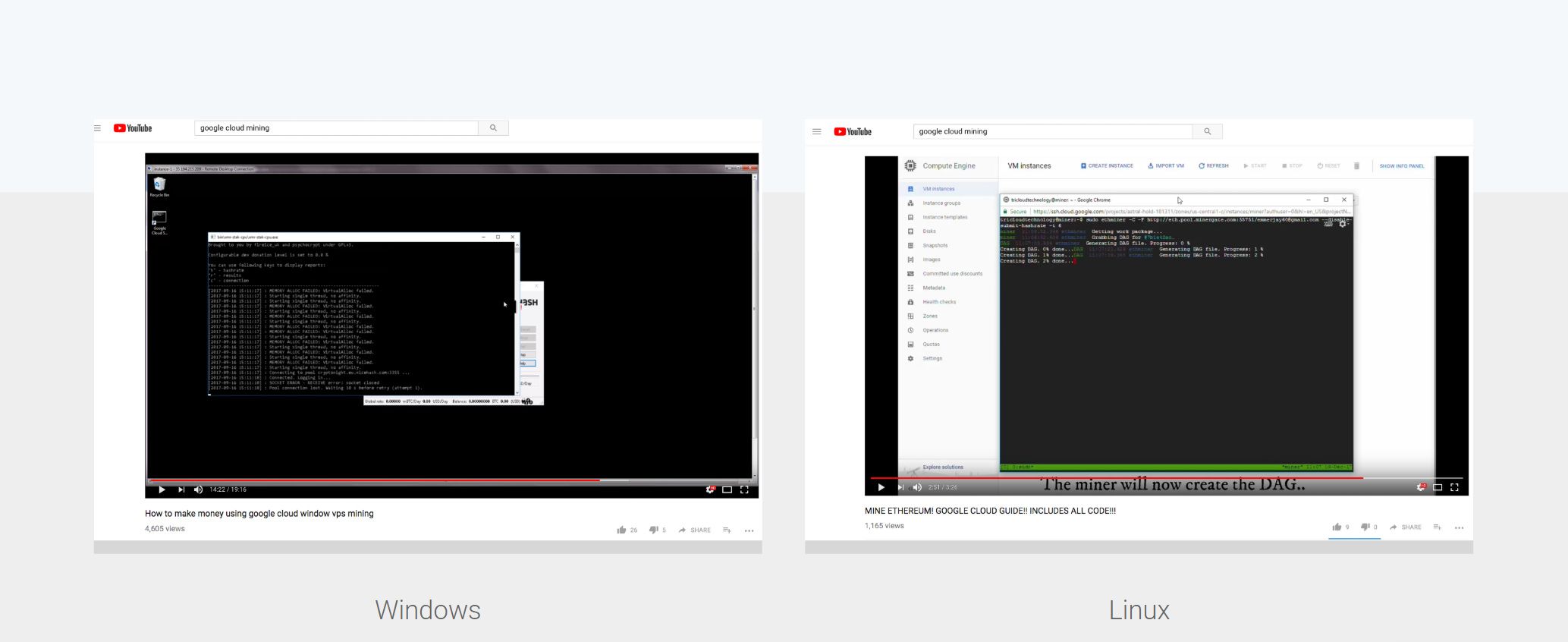
Very quickly, this type of attack became so popular that it led to thousands of people watching YouTube tutorials on how to mine on Google cloud (which is unprofitable under normal circumstances). Obviously, we couldn’t anticipate that abusive mining would become such a huge issue.
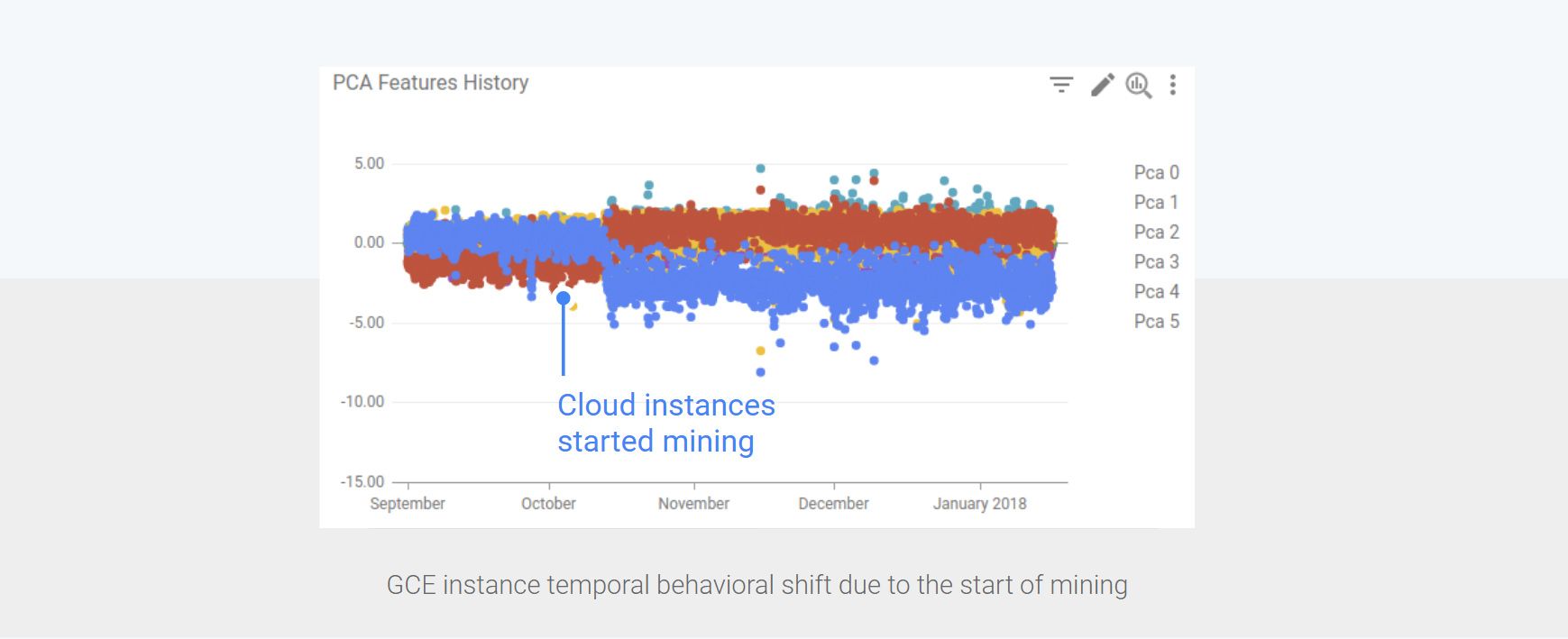
Fortunately, we did have an anomaly detection system in place for Google Cloud instances when that happened. As expected, and shown in the chart above which was taken directly from our anomaly detection system dashboard, it turns out that when instances start mining their temporal behavior shift drastically because the associated resource usage is fundamentally different from the traditional resource usage exhibited by uncompromised cloud instances. We were able to use this shift detection to curb this new vector of attacks, ensure that our cloud platform remains stable and warm GCE clients that they were compromised.
Data poisoning
The second class of attacks faced by classifiers relates to adversaries attempting to poison your data to make your system misbehave.
Model skewing
The first type of poisoning attack is called model skewing, where attackers attempt to pollute training data to shift the learned boundary between what the classifier categorizes as good input, and what the classifier categorizes as bad input. For example, model skewing can be used to try to pollute training data to trick the classifier to mark specific malicious binaries as benign.
Concrete example
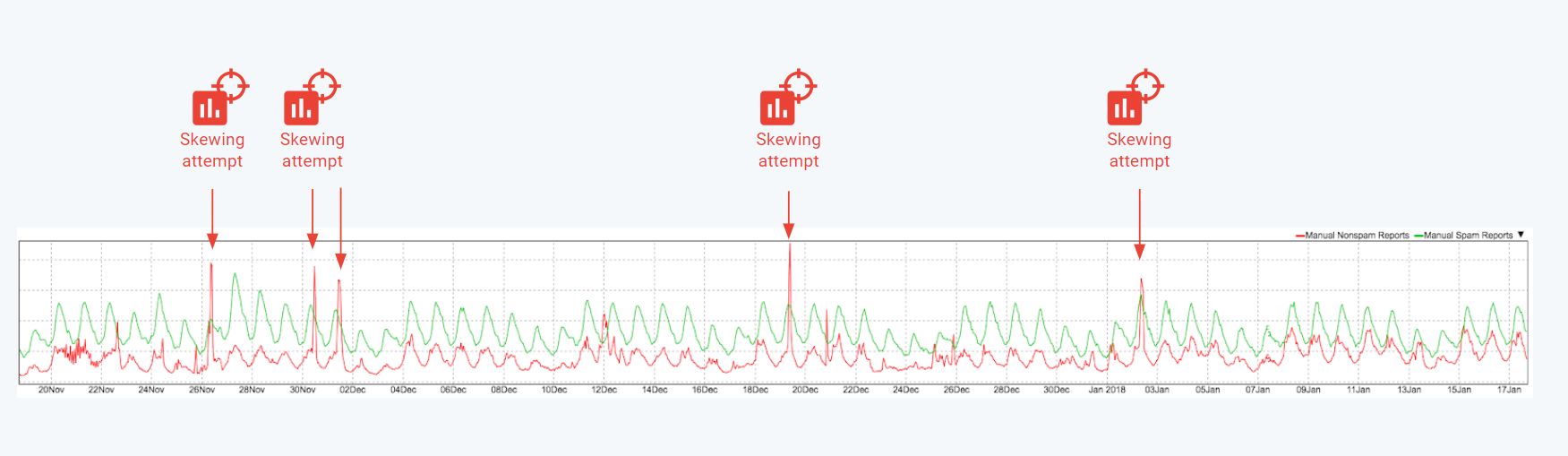
In practice, we regularly see some of the most advanced spammer groups trying to throw the Gmail filter off-track by reporting massive amounts of spam emails as not spam. As shown in the figure, between the end of Nov 2017 and early 2018, there were at least four malicious large-scale attempts to skew our classifier.
Thus, when designing an AI base defense, you need to account for the fact that:
Attackers actively attempt to shift the learned boundary between abusive and legitimate use in their favor.
Mitigation strategies
To prevent attackers from skewing models, you can leverage the following three strategies:
- Use sensible data sampling: You need to ensure that a small group of entities, including IPs or users, can’t account for a large fraction of the model training data. In particular, be cautious to not over-weighting false positives and false negatives reported by users. This can potentially be achieved by limiting the number of examples that each user can contribute, or using decaying weights based on the number of examples reported.
- Compare your newly trained classifier to the previous one to estimate how much has changed. For example, you can perform a dark launch and compare the two outputs on the same traffic. Alternative options include A/B testing on a fraction of the traffic, and backtesting.
- Build a golden dataset that your classifier must accurately predict in order to be launched into production. This dataset ideally contains a set of curated attacks and normal content that are representative of your system. This process will ensure that you can detect when a weaponization attack was able to generate a significant regression in your model before it negatively impacted your users.
Feedback weaponization
The second type of data poisoning attack is the weaponization of user feedback systems to attack legitimate users and content. As soon as attackers realize that you are using user feedback, one way or another—for penalization purposes—they will try to exploit this fact to their advantage.
Concrete examples
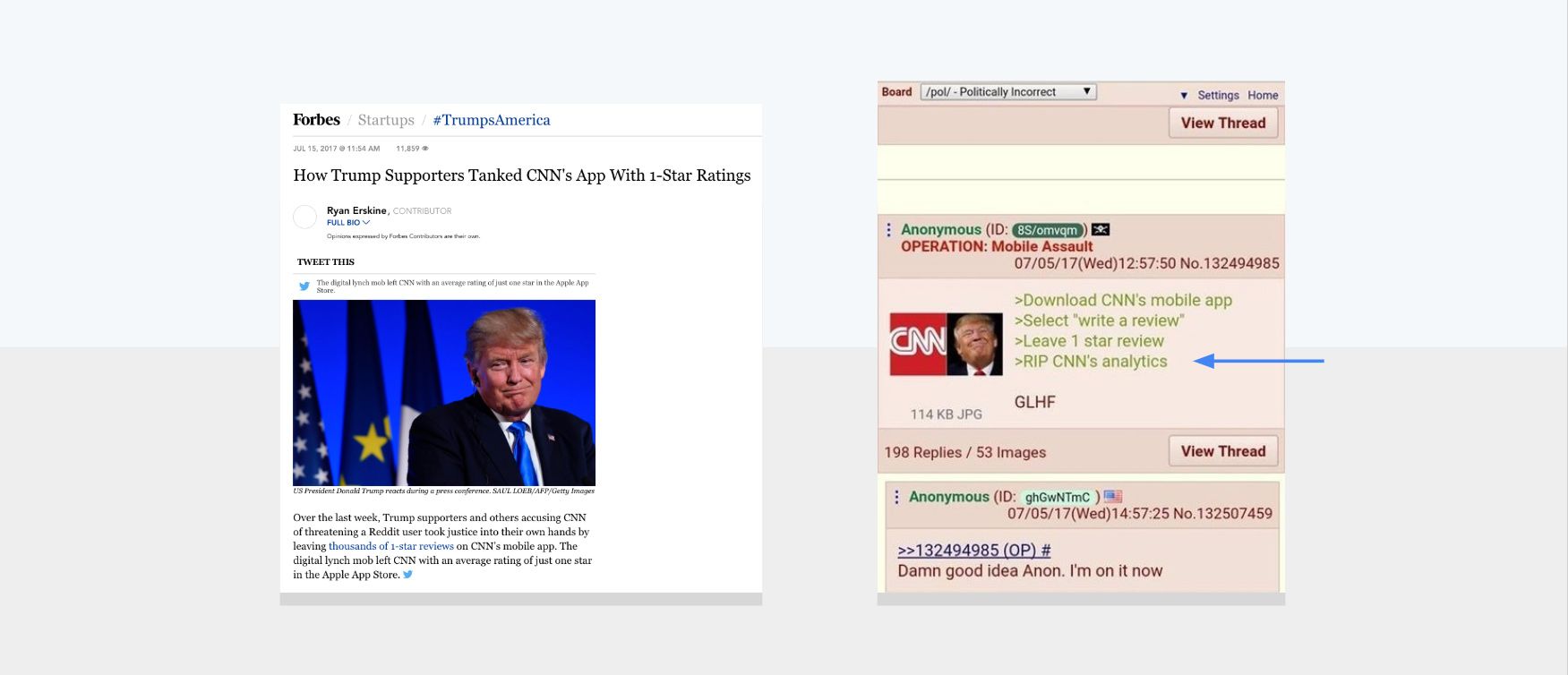
One of the most egregious attempts to weaponize user feedback we witnessed in 2017 was a group of 4chan users that decided to tank the CNN app ranking on the Play Store and App Store by leaving thousands of 1-star ratings.
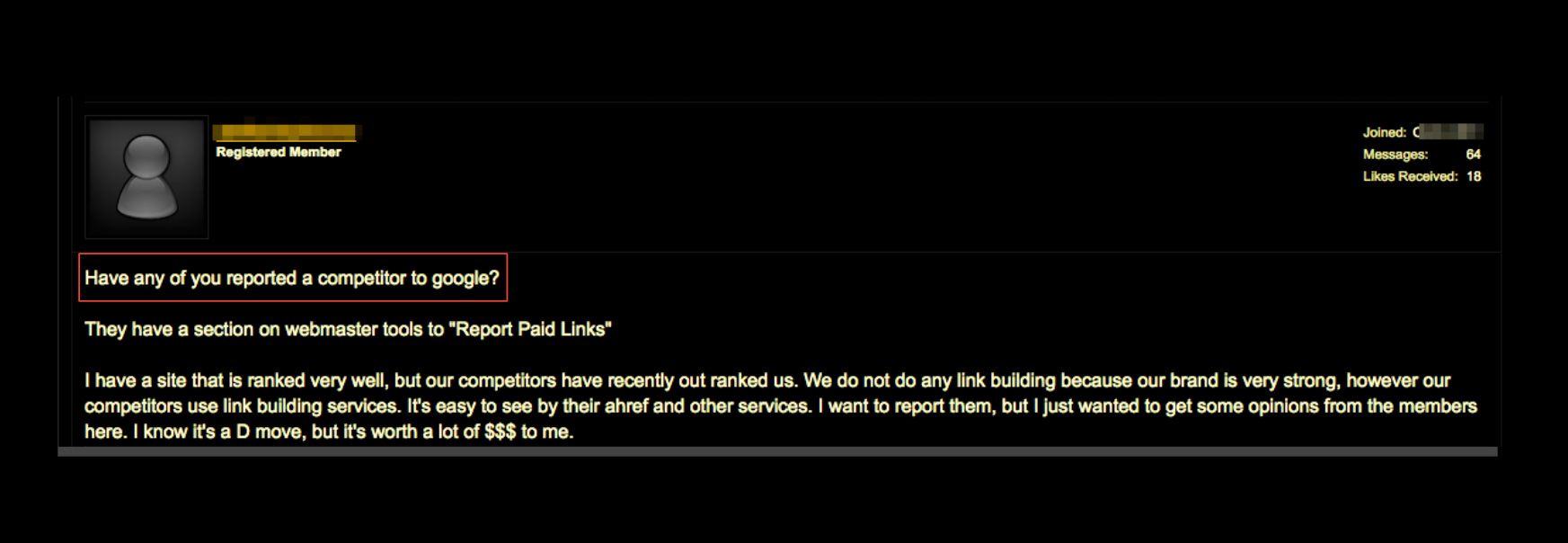
Feedback weaponization is actively used by bad actors for a number of reasons, including: attempting to take down the competition, exacting revenge, and covering their tracks. The screenshot above showcases a blackmarket post discussing how to “use Google” to take out a competitor.
Accordingly, while building your system you need to work under the assumption that:
Mitigation strategies
Here are the two key points to keep in mind while working on mitigating feedback weaponization:
- Don’t create a direct loop between feedback and penalization. Instead, make sure the feedback authenticity is assessed and combined with other signals before making a decision.
- Don’t assume that the owner of the content that is benefiting from the abuse is responsible for it. For example, it’s not because a photo has hundreds of fake likes that the owner may have bought it. We have seen countless cases where attackers juiced up legitimate content in an attempt to cover their tracks or try to get us to penalize innocent users.
Model-stealing attacks
This post would not be complete without mentioning attacks that aim to recover models or information about the data used during training. Such attacks are a key concern because models represent valuable intellectual property assets that are trained on some of a company’s most valuable data, such as financial trades, medical information or user transactions.
Ensuring the security of models trained on user-sensitive data such as cancer-related data is paramount as such models can potentially be abused to disclose sensitive user information.
Attacks
The two main model-stealing attacks are:
Model reconstruction: The key idea here is that the attacker is able to recreate a model by probing the public API and gradually refining his own model by using it as an Oracle. A recent paper showed that such attacks appear to be effective against most AI algorithms, including SVM, Random Forests and deep neural networks.
Membership leakage: Here, the attacker builds shadow models that enable him to determine whether a given record was used to train a model. While such attacks don’t recover the model, they potentially disclose sensitive information.
Defense
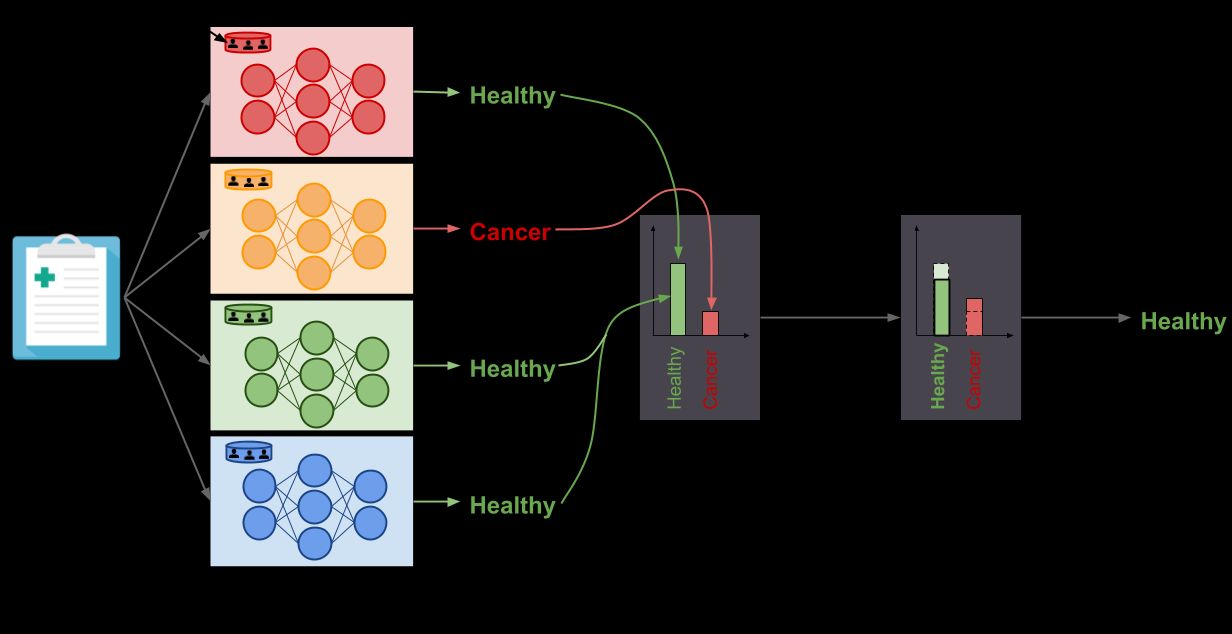
The best-known defense against model-stealing attacks is known as PATE (latest paper) —a privacy framework developed by Ian Goodfellow et al. As shown in the figure above, the key idea behind PATE is to partition the data and train multiple models that are combined to make a decision. This decision is then fudged with noise like other differential privacy systems.
To know more about differential privacy read Matt’s intro post. To know more about PATE and model stealing attacks read Ian’s post on the subject.
Conclusion
It’s about time to wrap up this (rather long!) series of posts on how to use AI to combat fraud and abuse. The key takeaway of this series (as detailed in the first post) is that:
AI is key to building protections that keep up with both users’ expectations and increasingly sophisticated attacks.
As discussed in this post and the two previous ones, there are some challenges to overcome to make this work in practice. However, now that AI frameworks are mature and well documented, there’s never been a better time to start using AI in your defense systems, so don’t let those challenges stop you as the upsides are very strong.
Thank you for reading this blog post up to the end. And please don’t forget to share it, so your friends and colleagues can also learn how to use AI for anti-abuse purposes.
To get notified when my next post is online, follow me on Twitter, Facebook, Google+, or LinkedIn. You can also get the full posts directly in your inbox by subscribing to the mailing list or via RSS.
A bientôt!


